BIOSCAN Shape and scene generation Articulated object understanding and generation Openable part detection Human-object interactions Text-image-shape embeddings Understanding language in 3D scenes Embodied AI 3D datasets
BIOSCAN
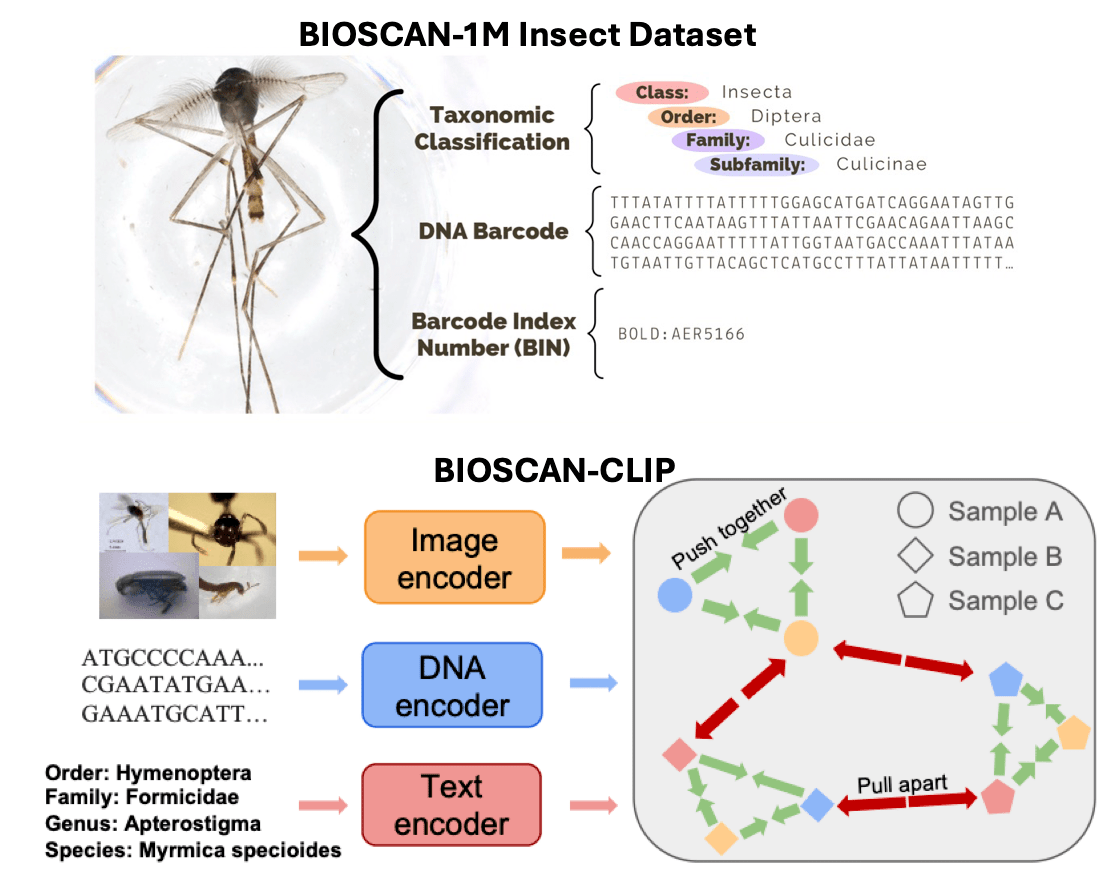
Monitoring and understanding the biodiversity of our world is becoming increasingly critical. BIOSCAN is a large, inter-disclinary effort lead by the International Barcode of Life (iBOL) Consortium to develop a global biodiversity monitoring system. As part of this larger project, we have ongoing collaborations with University of Guelph and University of Waterloo to explore how to use recent development in machine learning to assist with biodiversity monitoring. As a first step, we have introduced datasets (BIOSCAN-1M,BIOSCAN-5M) and developed self-supervised and multimodal models for taxononomic classification (BarcodeBERT,CLIBD).
BIOSCAN-1M BIOSCAN-5M BIOSCAN cropping tool BarcodeBERT CLIBDShape and scene generation
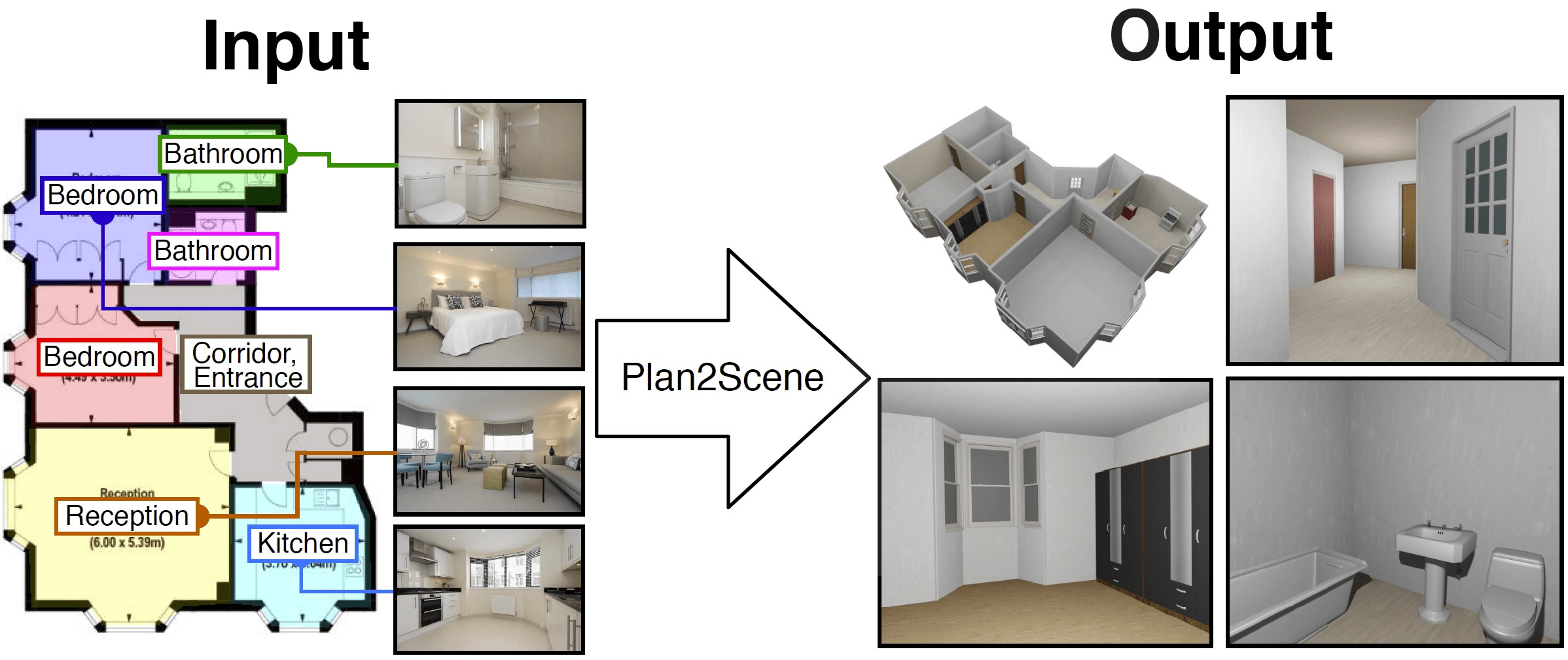
We have a series of projects on shape and scene generation, including exploring different representations (Object images), and generating shapes from text (PureCLIPNeRF), and creating scenes from single-view image (Diorama) and floorplans (Plan2Scene).
Shape generation Object images PureCLIPNeRF Survey on Text-to-3D shape generationScene generation SceneMotifCoder Diorama NuiScene SemLayoutDiff HSM Plan2Scene
Articulated object understanding and generation

Everyday indoor environments are filled with interactable, articulated objects. We aim to be able to create such interactive environments. To better understand the types of articulated objects found in the real-world, we introduce MultiScan, a dataset of 3D scans of annotated parts and articulation parameters. We also work on the reconstruction of articulated objects from two views (PARIS) and generative models for creating new articulated objects (CAGE).
MultiScan PARIS CAGE SINGAPO S2O Survey on articulated objectsOpenable part detection
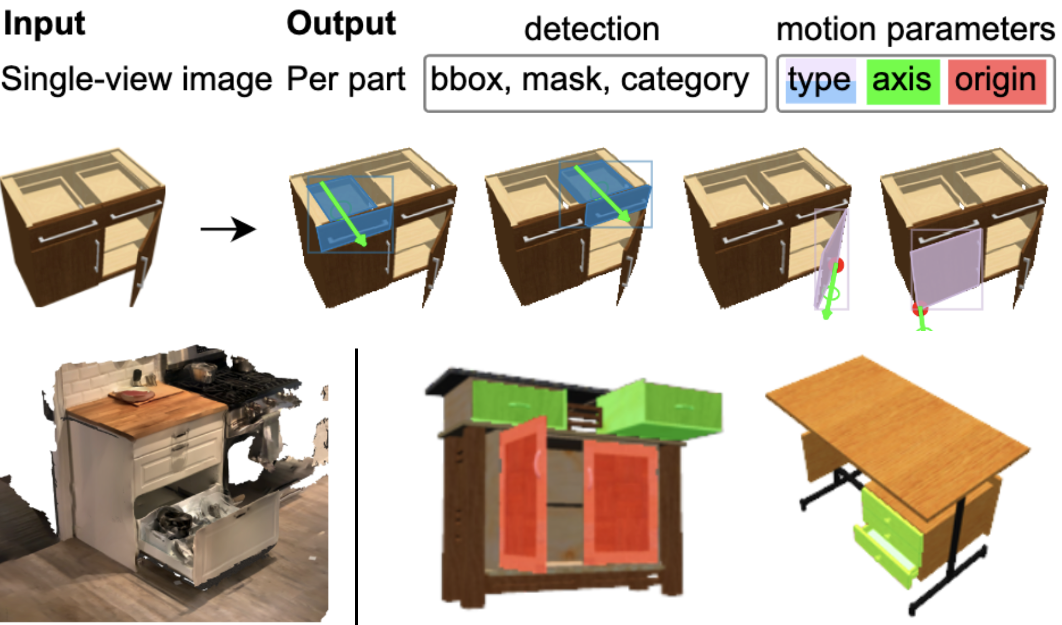
We address the task of predicting what parts of an object can open and how they move when they do so. The input is a single image of an object, and as output we detect what parts of the object can open, and the motion parameters describing the articulation of each openable part. We introduce the task of Openable-Part Detection (OPD), and extend it to images with multiple objects in OPDMulti.
OPD OPDMultiHuman-object interactions
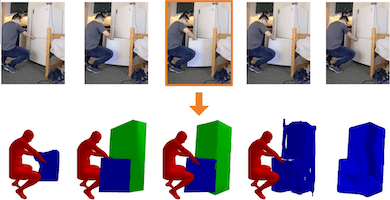
Human-object interactions with articulated objects are common in everyday life, but it is challenging to infer an articulated 3D object model from an RGB video showing a person manipulating the object. In 3DHOI, we canonicalize the task of articulated 3D human-object interaction reconstruction from RGB video, and carry out a systematic benchmark of four methods for this task: 3D plane estimation, 3D cuboid estimation, CAD model fitting, and free-form mesh fitting.In iTACO, we introduce a coarse-to-fine framework and a synthetic dataset of 784 videos containing 284 objects across 11 categories.
3DHOI iTACOText-image-shape embeddings
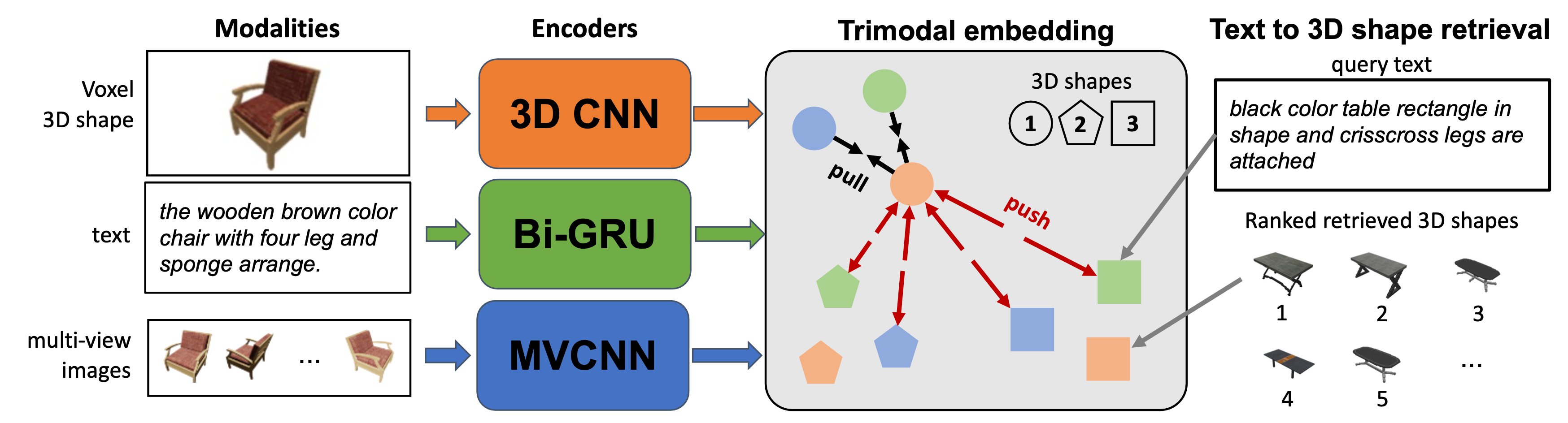
We have several projects that investigates the use of contrastive loss to build a trimodal embedding space over text, images, and shapes for text-to-image retrieval.
TriColo DuoduoCLIPUnderstanding language in 3D scenes
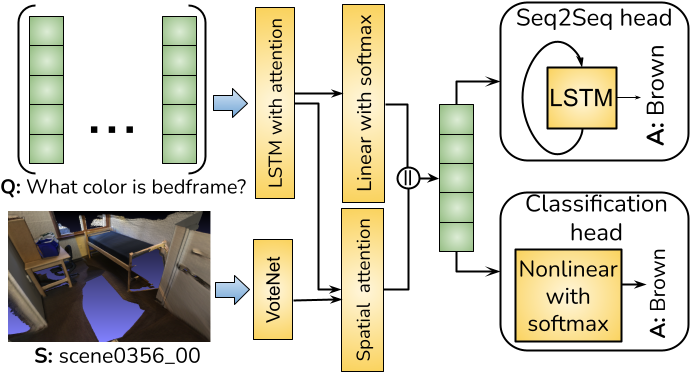
We propose the task of visual grounding (ScanRefer) and dense captioning (Scan2Cap) in 3D scenes and introduce datasets. To study the tasks, we propose baselines, and models that combine the two tasks (D3Net and Unit3D). In Multi3DRefer, we extend the visual grounding task to the more realistic setting where each language description can correspond to multiple objects. We also address 3D Visual Question Answering in 3DVQA.
ScanRefer Scan2Cap D3Net UniT3D Multi3DRefer 3D VQA ViGiL3DEmbodied AI

Works on embodied AI study how agents can move in a space give sensory input (e.g. RGB, depth frames) and instructions or specifications for a target goal. We have works that look at following natural language instructions (LAW), as well as proposing and benchmarking new tasks such as the Multi-Object Navigation (MultiON) task, where an agent needs to navigate to multiple objects in a given sequence.
Simulators Habitat Sapien MinosTasks MultiON task MultiON challenge CoMON LangNavBench HomeRobot
Methods MOPA (modular approach) LAW (VLNCE) LIFGIF for OC-VLN
Survey Mapping for indoor emboded AI
3D datasets
We have worked on a number of different datasets for 3D, ranging from 3D shapes (ShapeNet), compositional 3D scenes (HSSD), to scanned environments (HM3D) and articulated objects (PartNet Mobility, OPDReal) and scenes (MultiScan).
3D shapes HSSD ShapeNet PartNet PartNet Mobility OPDReal3D scenes HSSD R3DS HM3D HM3D-Semantics MultiScan Matterport3D ScanNet
3D and language ScanRefer Scan2Cap Multi3DRefer 3D VQA ViGiL3D
3D annotations for images Mirror3D