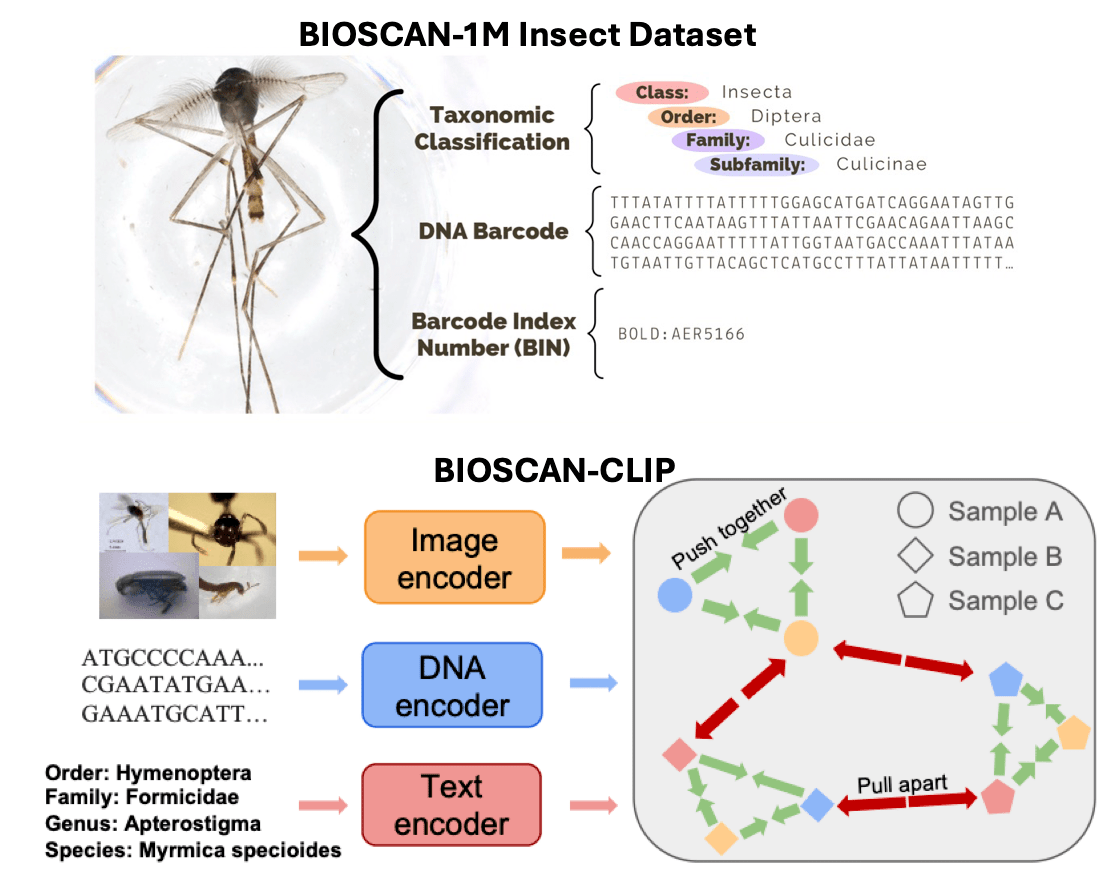
BIOSCAN
Monitoring and understanding the biodiversity of our world is becoming increasingly critical. BIOSCAN is a large, inter-disclinary effort lead by the International Barcode of Life (iBOL) Consortium to develop a global biodiversity monitoring system. As part of this larger project, we have ongoing collaborations with University of Guelph and University of Waterloo to explore how to use recent development in machine learning to assist with biodiversity monitoring. As a first step, we have introduced datasets (BIOSCAN-1M,BIOSCAN-5M) and developed self-supervised and multimodal models for taxononomic classification (BarcodeBERT,CLIBD).