Abstract
We propose a simple but effective modular approach MOPA (Modular ObjectNav with PointGoal agents) to systematically investigate the inherent modularity of the object navigation task in Embodied AI. MOPA consists of four modules: (a) an object detection module trained to identify objects from RGB images, (b) a map building module to build a semantic map of the observed objects, (c) an exploration module enabling the agent to explore the environment, and (d) a navigation module to move to identified target objects. We show that we can effectively reuse a pretrained PointGoal agent as the navigation model instead of learning to navigate from scratch, thus saving time and compute. We also compare various exploration strategies for MOPA and find that a simple uniform strategy significantly outperforms more advanced exploration methods.
Approach: Modular-MON
In the MultiON task, the agent is given the current goal gi from a set of N goals {g1, g2, ..., gN }. Once the agent has reached gi and generated the Found action successfully, it is given the next goal gi+1. This continues until the agent has found all the goals in the episode. In Modular-MON, we take a modular approach to multi-object navigation by employing the following modules: (1) Object detection (O), (2) Map building (M), (3) Exploration (E) and (4) Navigation (N ). These modules are intuitively weaved together. Modular-MON identifies objects (O) by observing the environment and builds a semantic map (M) by projecting information about category labels of the objects (i.e. semantics) in the field of view. If the agent has not yet discovered the current goal, gi, it will continue to explore (E). Once the current goal has been discovered, Modular-MON plans a path from its current location to the goal, and generates actions to navigate (N) towards the goal. We experiment with different exploration and navigation strategies to systematically investigate their contribution to the agent performance.
Results
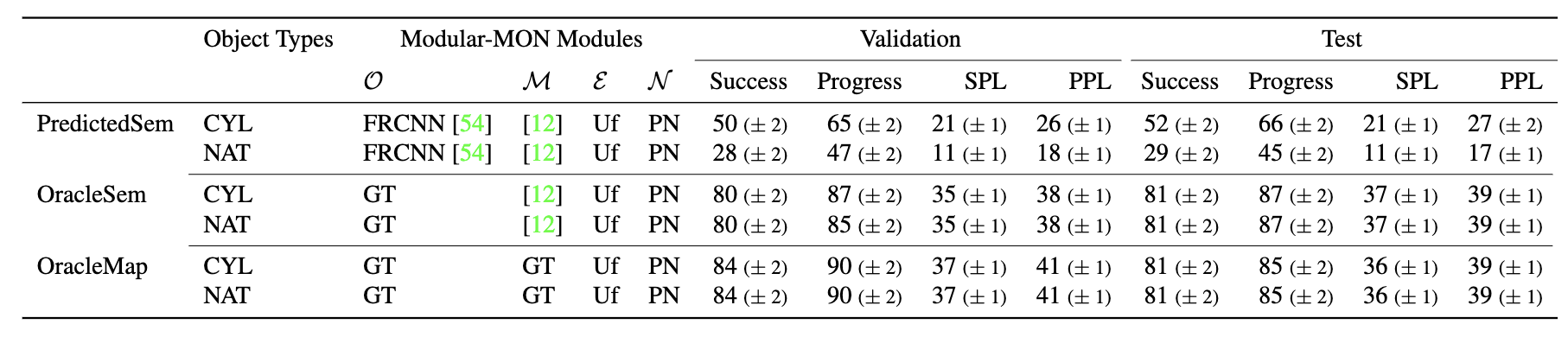
We observe that the PredictedSem agent, which builds a map (M) using predicted semantic labels (O), performs better on cylinder (‘CYL’) objects than natural (‘NAT’) objects. We compare its performance with two oracle agents, OracleMap and OracleSem where ground-truth (‘GT’) is provided for either the mapping or object semantics. As expected, the performance are mostly identical for the two object types for OracleMap and OracleSem, since the placement of the objects are the same for both, with OracleMap outperforming OracleSem. These methods use Uniform Top-down Sampling w/ Fail-Safe (‘Uf’) as the Exploration (E) module and PointNav [52 ] (‘PN’) as the Navigation (N ) module.
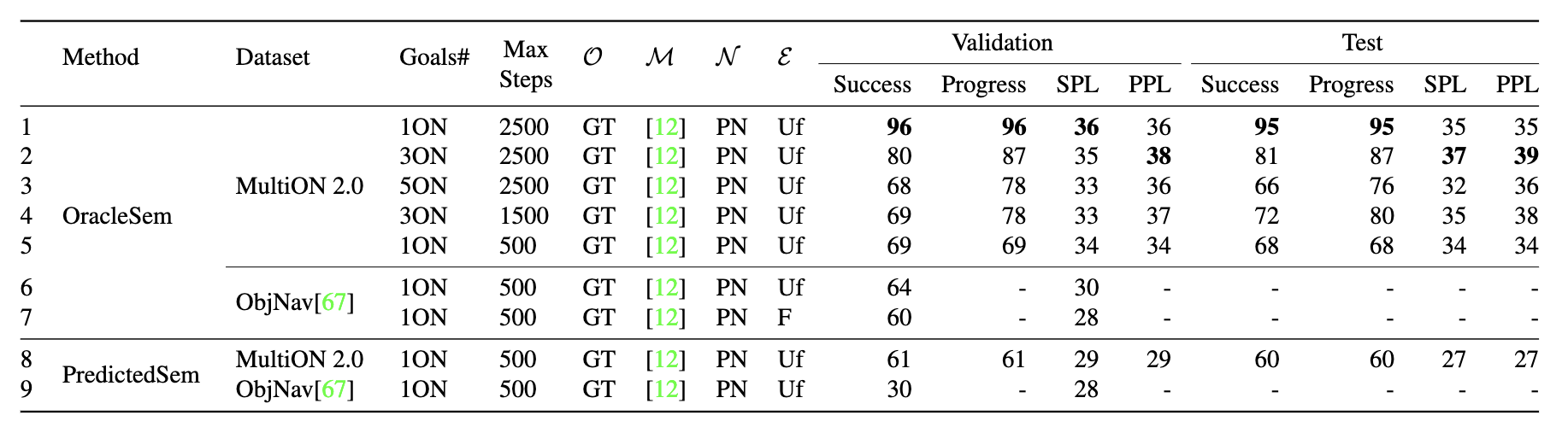
We also investigate how our Modular-MON performs on the Object Goal Navigation (ObjectNav) task in the above table. We observe that the performance deteriorates as we increase target objects, for a fixed step limit (rows 1-3). Our OracleSem performs similarly on the Habitat ObjectNav 2022 and MultiON 2.0 1ON val set (rows 5,6) when we set the step limit to 500 steps, following ObjectNav task setting. In ObjectNav, OracleSem performs better (rows 6,7) with Uniform Top-down Sampling w/ Fail-Safe (Uf) than Frontier (F). Moreover, our PredictedSem performs better on MultiON2.0 than on ObjectNav (rows 8,9).
Below, we show a rollout of one of our episodes containing one target object.
Error Modes
In the MultiON task, Modular-MON fails due to the agent running out of step limit, or stopping at a location far away from the goal. For those cases where the agent ran out of steps, it either has not yet discovered the goal or has discovered the goal but failed to stop within 1m of it.
Modular-MON fails on the ObjectNav task mostly because the agent ran out of steps. Some episodes fail even when the agent is within 1m of the goal bounding box with the goal in sight, indicating that the viewpoints sampled for determining success in ObjectNav are sparse.
Citation
@InProceedings{Raychaudhuri_2024_WACV,
author = {Raychaudhuri, Sonia and Campari, Tommaso and Jain, Unnat and Savva, Manolis and Chang, Angel X.},
title = {MOPA: Modular Object Navigation With PointGoal Agents},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month = {January},
year = {2024},
pages = {5763-5773}
}
Acknowledgements
The members at SFU were supported by Canada CIFAR AI Chair grant, Canada Research Chair grant, NSERC Discovery Grant and a research grant by Facebook AI Research. Experiments at SFU were enabled by support from WestGrid and Compute Canada. TC was supported by the PNRR project Future AI Research (FAIRPE00000013), under the NRRP MUR program funded by the NextGenerationEU. We also thank Angelica, Jiayi, Shawn, Bita, Yongsen, Arjun, Justin, Matthew, and Shivansh for comments on early drafts of this paper.