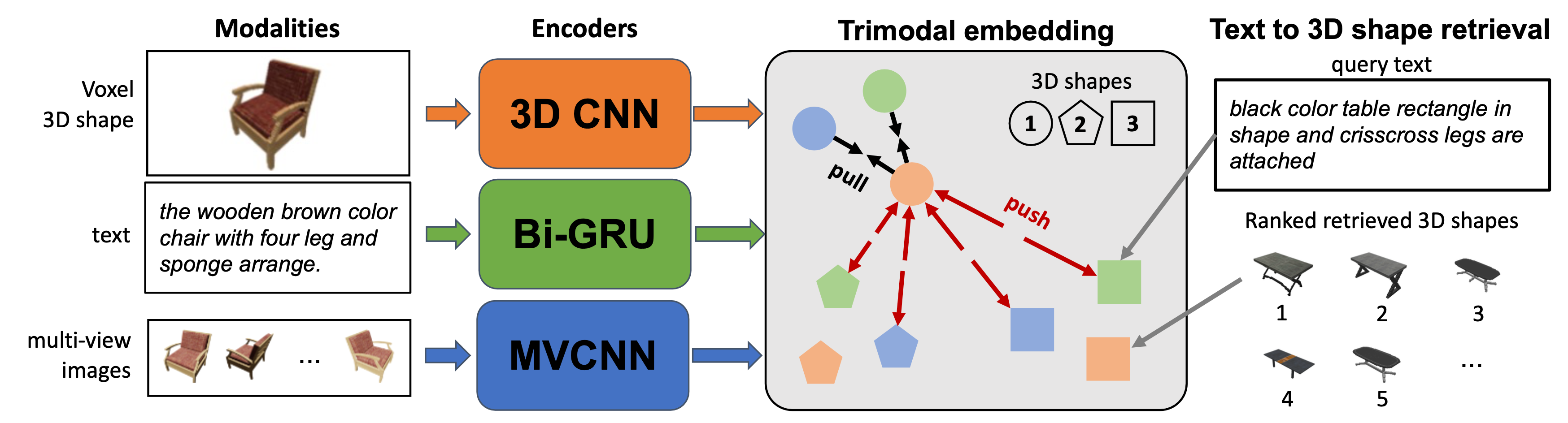
Text-to-shape retrieval is an increasingly relevant problem with the growth of 3D shape data. Recent work on contrastive losses for learning joint embeddings over multimodal data has been successful at tasks such as retrieval and classification. Thus far, work on joint representation learning for 3D shapes and text has focused on improving embeddings through modeling of complex attention between representations, or multi-task learning. We propose a trimodal learning scheme over text, multi-view images and 3D shape voxels, and show that with large batch contrastive learning we achieve good performance on text-to-shape retrieval without complex attention mechanisms or losses. Our experiments serve as a foundation for follow-up work on building trimodal embeddings for text-image-shape.
Video
Overview
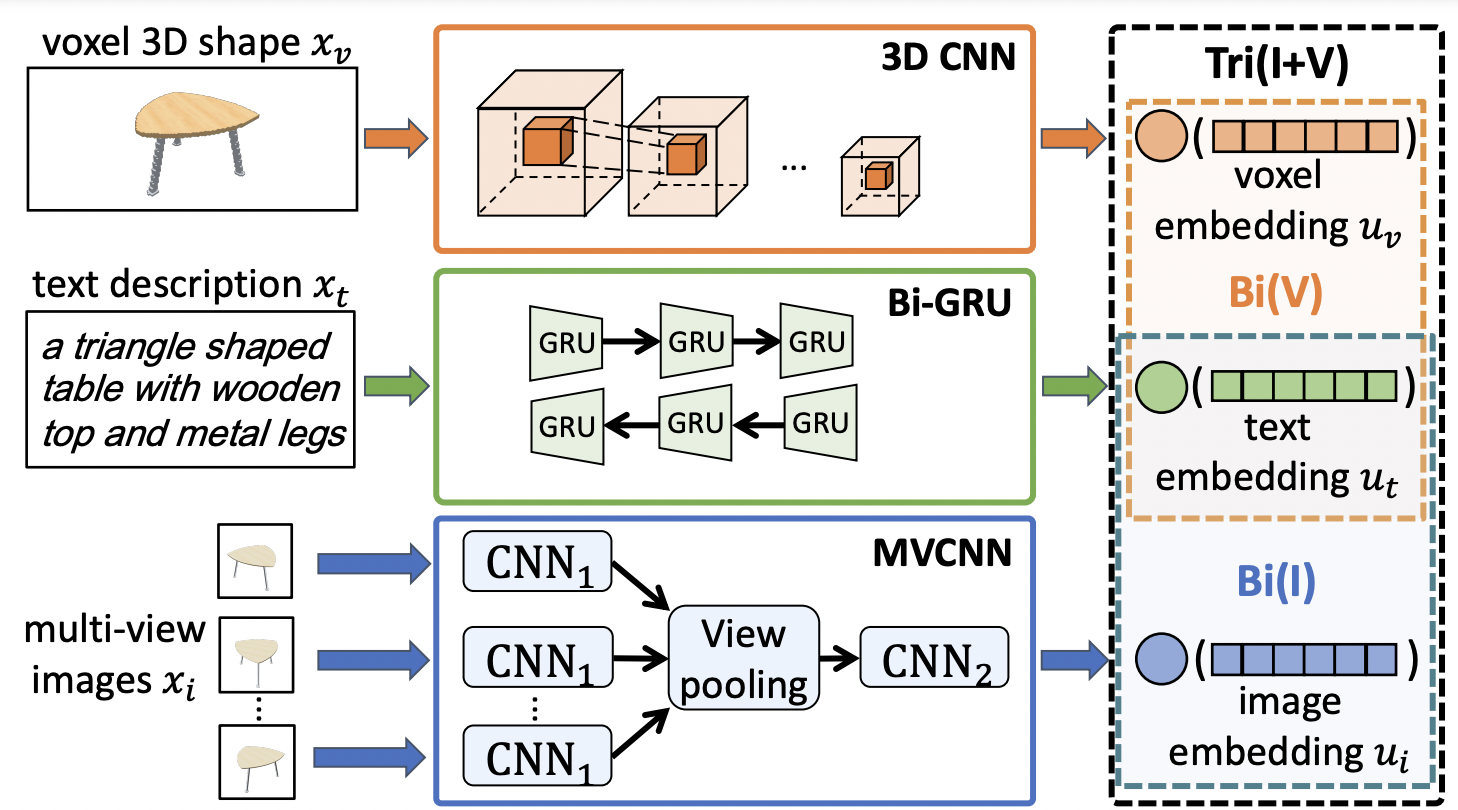
For each modality, we define an encoder that takes the input and outputs an encoding. The text encoder is a Bi-directional Gate Recurrent Unit (Bi-GRU) which takes a text description and outputs the embedding. For voxels we use a 3D CNN model that takes a 3D input and outputs a voxel embedding. Finally, the image encoder takes M views of the object through an MVCNN architecture with pretrained ResNet18 backbone to obtain the image representation. Variants of our model include just two modalities(Bi) and all three modalities(Tri). For the bimodal models, we only consider text and image(I), or text and voxels(V). For the trimodal models, we consider text, image and voxels(I+V).
Paper
