Applications
Populating Scene
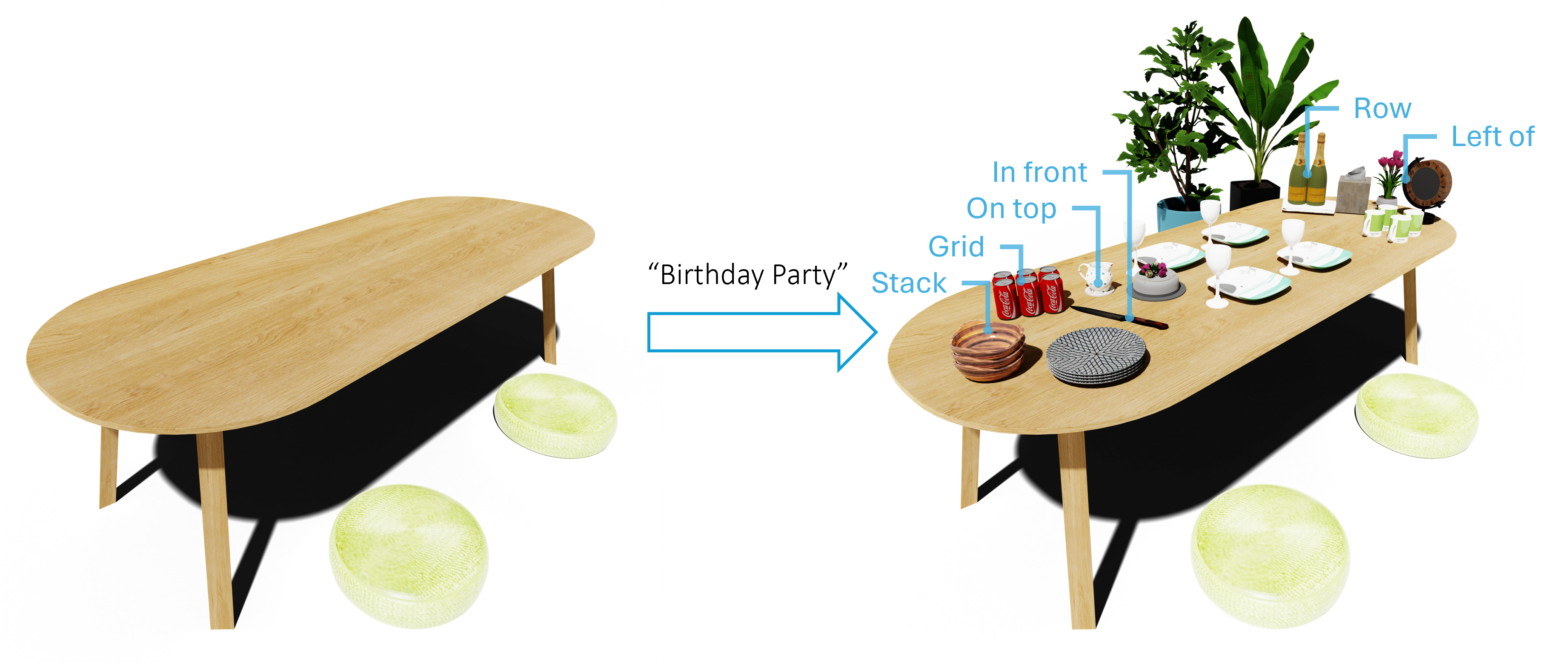
We populate an indoor scene with dense, realistic object arrangements by instantiating a variety of learned motifs. The dining table shown here is populated by instantiating arrangements from six motif types. Note that the small object arrangements are essential for conveying specific scene states — e.g., a birthday party
Meta-Program Editing
We edit a learned stack motif meta-program to introduce an additional object category at the top of the stack. The edited meta-program preserves the generality of the original while adapting the motif with a user modification. On the right is a generated arrangement of "a stack of three plates and a cup" using this edited meta-program.
