Abstract
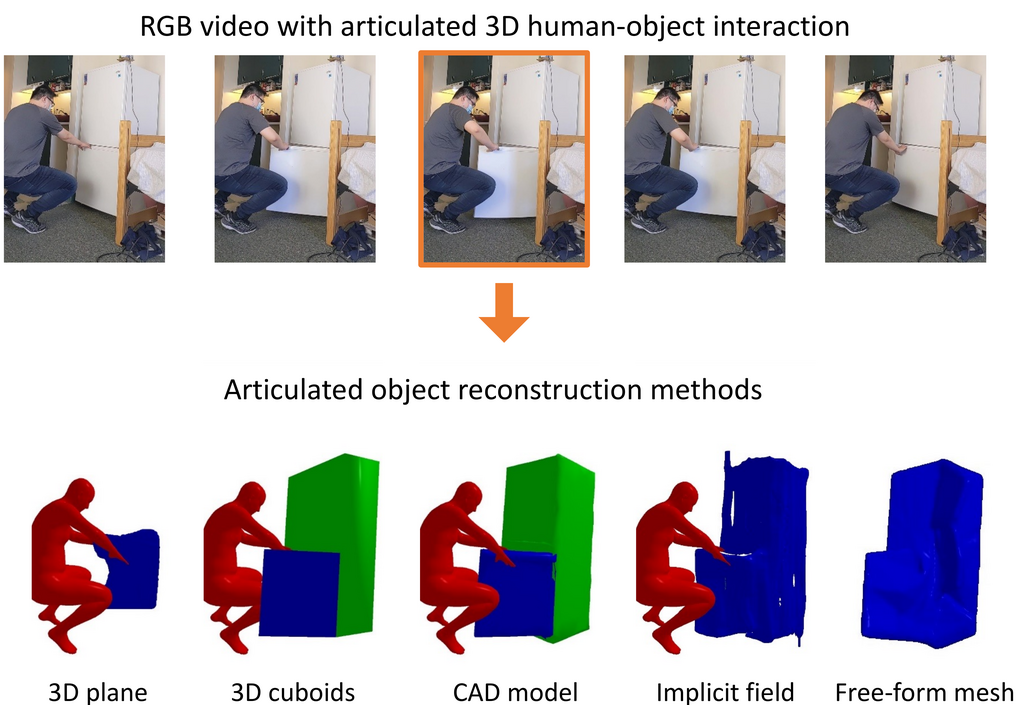
Human-object interactions with articulated objects are common in everyday life. Despite much progress in single-view 3D reconstruction, it is still challenging to infer an articulated 3D object model from an RGB video showing a person manipulating the object. We canonicalize the task of articulated 3D human-object interaction reconstruction from RGB video, and carry out a systematic benchmark of four methods for this task: 3D plane estimation, 3D cuboid estimation, CAD model fitting, and free-form mesh fitting. Our experiments show that all methods struggle to obtain high accuracy results even when provided ground truth information about the observed objects. We identify key factors which make the task challenging and suggest directions for future work on this challenging 3D computer vision task.
Video
Paper
